

Verification and validation concepts, strategies, and limitations
In the end, the discipline of verification is what separates journalism from entertainment, propaganda, fiction, or art. - Bill Kovach

Because I'm human, I am not perfect, and I make mistakes. So does everyone else, regardless of the work that they do - whether specifying, managing, designing, implementing, verifying, or delivering a product or service.
Root causes of error
The root causes of such human errors are well documented, and can be categorized into three classes:
Skill-based slips and lapses, in which outcomes deviate from intentions because of forgetfulness, misapplication, or lack of awareness during execution.
Procedural inadequacies, in which well-meaning processes fail to provide the necessary guidance for consistent execution, often due to descriptive instructions rather than prescriptive ones.
Knowledge-based mistakes, in which proper procedures are followed, but the foundational information provided is flawed, leading to failed execution.
To counteract these injection points, development methods must include filtering mechanisms that uncover and address such defects. This serves two purposes:
Detecting mistakes introduced during development close to where they are injected, to minimize rework costs
Confirming that outcomes achieve intended results, and in form, fitness, function, and at scale.
Since even these filtering processes themselves are subject to error, we must organize assurance activities with care and discipline. Integration is demanding. It seeks not just technical alignment, but also the removal of embedded defects to an acceptable level. This demands oversight, iteration, and realistic standards of “good enough.”
Refining the approach
Since errors inevitably occur - even within the filtering processes themselves - our methods must be intentionally and rigorously organized. Integration demands meticulous planning and oversight. Its role is to heighten the chances of identifying and eliminating previously introduced defects to an acceptable threshold of quality.
Since verification efforts are prone to error, we complement them with validation activities. These ensure not only that we’re crafting the right solution, but also that agents are performing transformations correctly. However, this layered assurance strategy increases the cost of aligning concurrent design and implementation efforts to intended (and potentially evolving) outcomes, while keeping undesired consequences within acceptable limits.
Integration across teams inevitably encounters a range of challenges: breakdowns in communication, shifting or insufficient definitions of intent, and the added complexity of navigating environmental constraints, organizational structures, and the orchestration performed by work package providers. These layered obstacles make consistent alignment a formidable but essential task.
Sharpening the focus
In complex systems, no realistic amount of testing can guarantee the absence of all issues. That’s because it's fundamentally impossible to prove a negative. Verification, then, isn’t about asserting perfection. It’s about uncovering defects, isolating symptoms, and qualifying whether a solution meets its intended purpose under practical, constrained conditions.
All assurance efforts are inherently limited by scope, coverage, and relevance - and those limits introduce risk. Unexamined situations may lurk beyond our detection thresholds, poised to trigger failures downstream. Given this, the purpose of verification is not to confirm the absence of error, but to discover enough of the right issues to fuel improvement. It reveals where a system diverges from intention, where gaps persist, and how well outcomes align with stakeholder expectations. In doing so, it builds confidence (not certainty) and sharpens the pathways from what exists to what was envisioned.
But our ability to discover errors worsens significantly as complexity, novelty, and criticality increases, since such a discovery requires that the error be visible under a specific circumstance. Most requirements describe only a subset of these circumstances, but not the whole enchilada. The rest of this footprint is made up of combinations of states, input spaces, and component interactions that typically explode beyond what can systematically be exercised without consideration of all this information, and the many ways that errors themselves can be injected into a design.
Navigating limitations of evaluations
We simply can't exhaustively test every scenario. All assurance efforts, however diligent, remain inherently constrained in scope, coverage, and relevance. This leaves residual risk: the possibility that unexamined conditions or overlooked combinations may lead the solution to fail in practice.
We must prioritize the time and resources we have available to explore a proper subset of these inputs and states and design our explorations, so we cover the most important and uncharted territory. When testing, we must organize the work by defining a series of testing sequences and conditions which will probe the system's behavior under different operational scenarios and activate threads that adequately traverse our systems' state space as actually built and installed, rather than what was defined, designed, or intended.
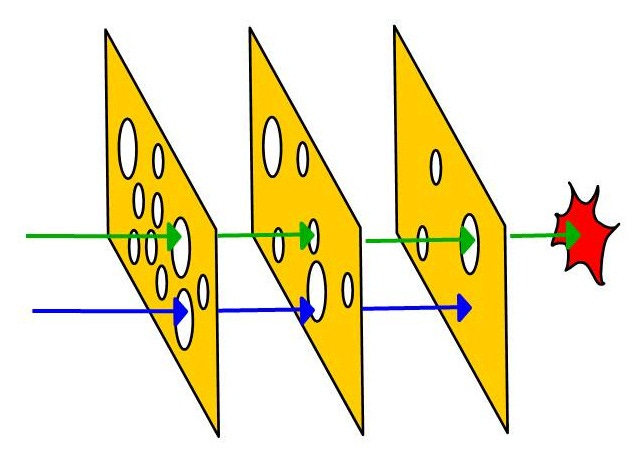
But latent errors will inevitably still be out there, like holes in Swiss cheese (Figure 1). Adequate filtering is thus achieved by phases of verification which each have value while also risking overlap in the coverage that can be provided. A defense in depth strategy in this environment can be effective, if the slices don't contain gaps that defects can sneak through.
How small can our footprint be for verification, while still providing the information necessary for assuring that the system will behave properly in service? This has been a classic (and unsolved) problem in testing research for years and was the basis for the introduction of 'structural coverage' into certification guidance for software-intensive systems early in my career. Whether a given set of tests achieves adequate coverage or not depends upon many factors, including the fidelity of the test environment, the stability of the article being tested, and the interactions of the design elements that realistically can be evaluated in isolation vs in situ. Of course, the robustness of the development process itself and the effectiveness of the agents that perform it are equally relevant.
But one will only be able to accurately assess whether a target coverage has been realized after a system enters service, and the real world closes the loop on whether expectations for product quality and performance have been realized, and that those expectations themselves were robust and comprehensive. Predicting this quality with acceptable confidence before a system enters service is a particularly risky proposition since our lenses are usually rose-colored. However, if we plan for it, it is possible to get scoping indicators about how many defects will need to be removed, and how effective the defect filtering processes of a development and production process are, by monitoring the extent and nature of the defects we discover as we move through stages of development. To understand why this helps, it's important to nail down some terms that provide a semantic framework for the associated concepts.
Some definitions
Clarity demands specificity. Before digging further into strategies or limitations, it's essential to disambiguate what we're talking about. Here's a quick calibration:
Verification demonstrates whether a product or service meets specified requirements. It answers the question: “Did we build it correctly?” This is typically achieved through inspection, analysis, and testing against documented criteria. It includes evaluating execution fidelity, compliance to specifications, and the degree to which artifacts match expectations.
Validation demonstrates whether the solution fulfills its intended purpose for stakeholders. It asks: “Did we build the correct thing?” Validation evaluates outcomes in realistic or representative conditions to assess fitness for use, and centers on usefulness, relevance, and whether outcomes align with intent and need.
Evaluation encompasses broader judgment about worth or adequacy, often factoring in context, tradeoffs, and human interpretation. Assurance is a type of evaluation.
Qualification is typically concerned with establishing that something meets a defined set of standards or requirements—often to approve readiness or fitness for use under stated conditions.
Assessments can be informal or formal, qualitative or quantitative, and may apply throughout various life cycle stages to support decision-making, prioritize risks, or guide improvement.
Each of these terms operates at different conceptual levels, some at the level of execution, others upstream of that. Confusing them leads to misalignment in roles, responsibilities, and outcomes. So before orchestrating efforts, we must first reflect on what each term implies, where it applies, and how it's used. If you aren’t already conversant with the language and lifecycle of failures, read this.
Products fail - sometimes often! And despite the best intentions, designs don’t always transform all expectations adequately. Failures can be subtle or spectacular, but they invariably surface limitations in understanding, communication, execution, or context.
Not all failures stem from faulty transformations. Sometimes the ideas themselves were flawed. Other times, real-world conditions challenge even excellent designs. Still others expose gaps in coordination across agents and domains. What matters is not whether failure occurs (it always does) but whether our systems recognize and respond to failure in ways that minimize the impacts of those failures.
We learn from failures. But only when we can see them, attribute them, and synthesize what they reveal. That’s why verification isn’t just a filter. It’s a mechanism for learning, for identifying where and how defects originate, and for clarifying whether those discoveries lead to better decisions next time.
This process isn’t linear or easy. Failures rarely announce themselves with glowing neon signs. Their symptoms may be diffuse, their causes systemic, their solutions elusive. This is why structured verification efforts must do more than tick boxes. They must actively seek feedback, distinguish signal from noise, and help humans interpret what they find.
The other requirements
Beyond correctness and fitness, products must meet a constellation of additional requirements. Some will be explicit, others tacit. These include performance thresholds, safety margins, usability expectations, maintainability, compliance obligations, and others. And they often interact in unexpected ways, creating tension between what’s desirable, feasible, and affordable.
These quality criteria usually include both things that are easy to measure - such as throughput, latency, or capacity - and things that are less easily measured, such as usability or maintainability. Collectively, these are described as 'non-functional' requirements, and while some are amenable to prototyping and rapid iterative refinements, others are much more challenging to evaluate with any meaningful fidelity or regularity. These other requirements aren’t just technical—they’re social, economic, and regulatory. Their definitions may change over time or vary across stakeholders. Some emerge late, in reaction to observed outcomes. Others were implicit all along but only get articulated once something goes wrong.
Efforts to verify these requirements are shaped by how well they’re stated. If a requirement is vague, verification becomes guesswork. If a requirement is over-constrained, it may render competing requirements untenable. Verification must balance precision with flexibility, confirming intent without freezing it.
Critically, these requirements accumulate. They are not resolved in isolation but layered across phases and contexts. Verification must surface their implications, probe their conflicts, and trace their influence. Not just “Did it meet requirement X?” but “What happens when X interacts with Y under condition Z?” This layering challenges even experienced agents. Requirements propagate through interfaces, architectural decisions, and behavioral expectations. Unacknowledged dependencies distort outcomes. Verification provides a way to interrogate those dependencies, surfacing where assumptions lie and how they’re coupled to judgments in both design, transformation, and execution.
Requirements for methods
Assurance strategies must be tailored to the conditions of the work they’re meant to evaluate. No single method suffices across contexts, so selection must be informed by both the nature of what is being assured and the limitations of how assurance can be performed. To be effective, methods must:
Align with the intended outcomes Methods must be structured to evaluate against the criteria of success—not just compliance with process, but realization of objectives.
Accommodate domain-specific constraints Whether constrained by physics, policy, interface characteristics, or resource limitations, assurance must work within the bounds imposed by the endeavor.
Expose failure modes reliably Effective methods illuminate points of fragility—whether latent defects or emergent behaviors—so that responses can be formulated proactively.
Support reproducibility and traceability Results should be understandable, repeatable, and traceable back to both the evaluation intent and the observed evidence, enabling oversight and refinement.
Remain cost-aware and impact-sensitive Assurance isn't free. Methods must balance depth and breadth of evaluation with cost and potential disruption, preserving the integrity of both the work and the teams performing it.
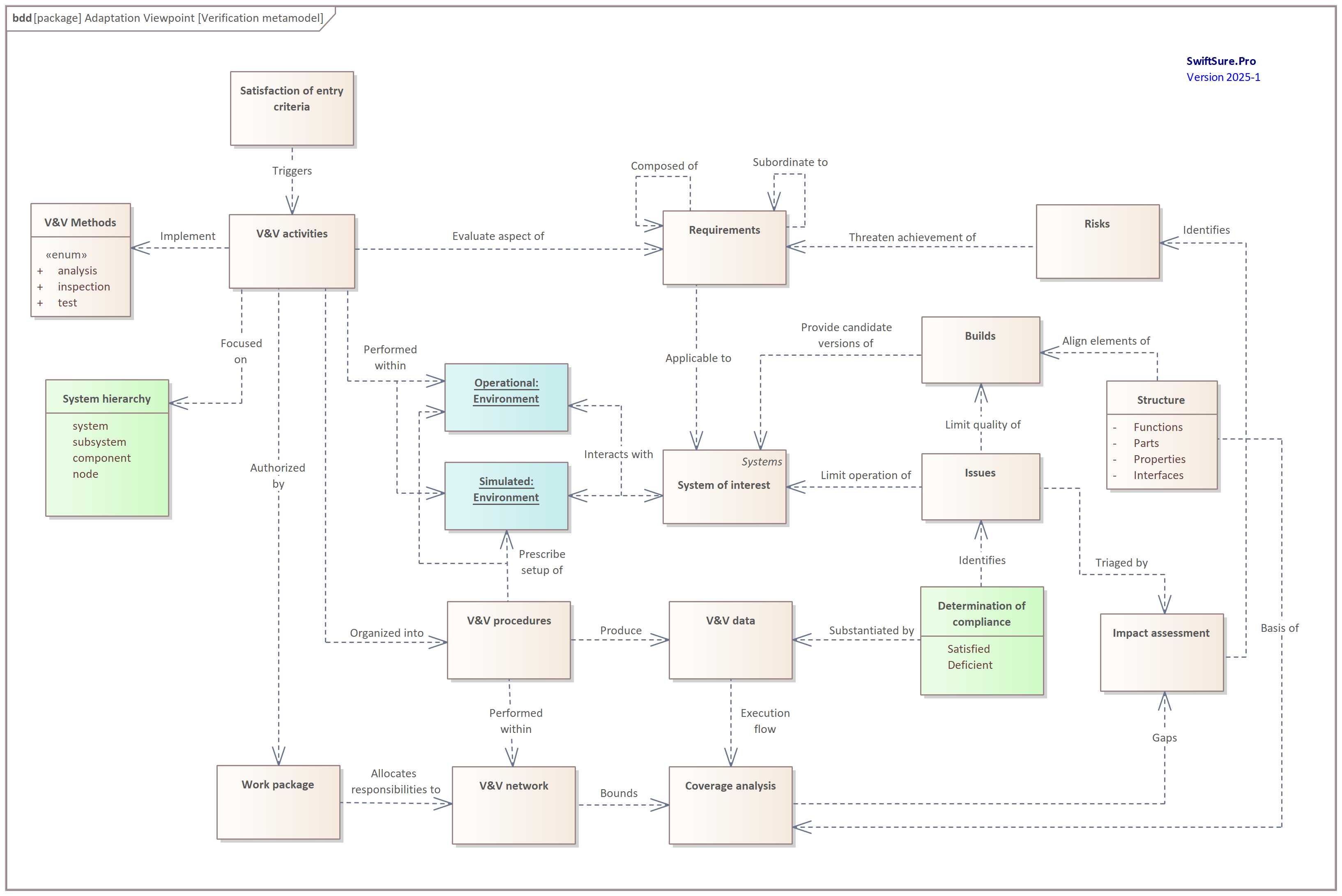
The work products of these methods must satisfy the verification metamodel depicted in Figure 2.
Troubleshooting defects
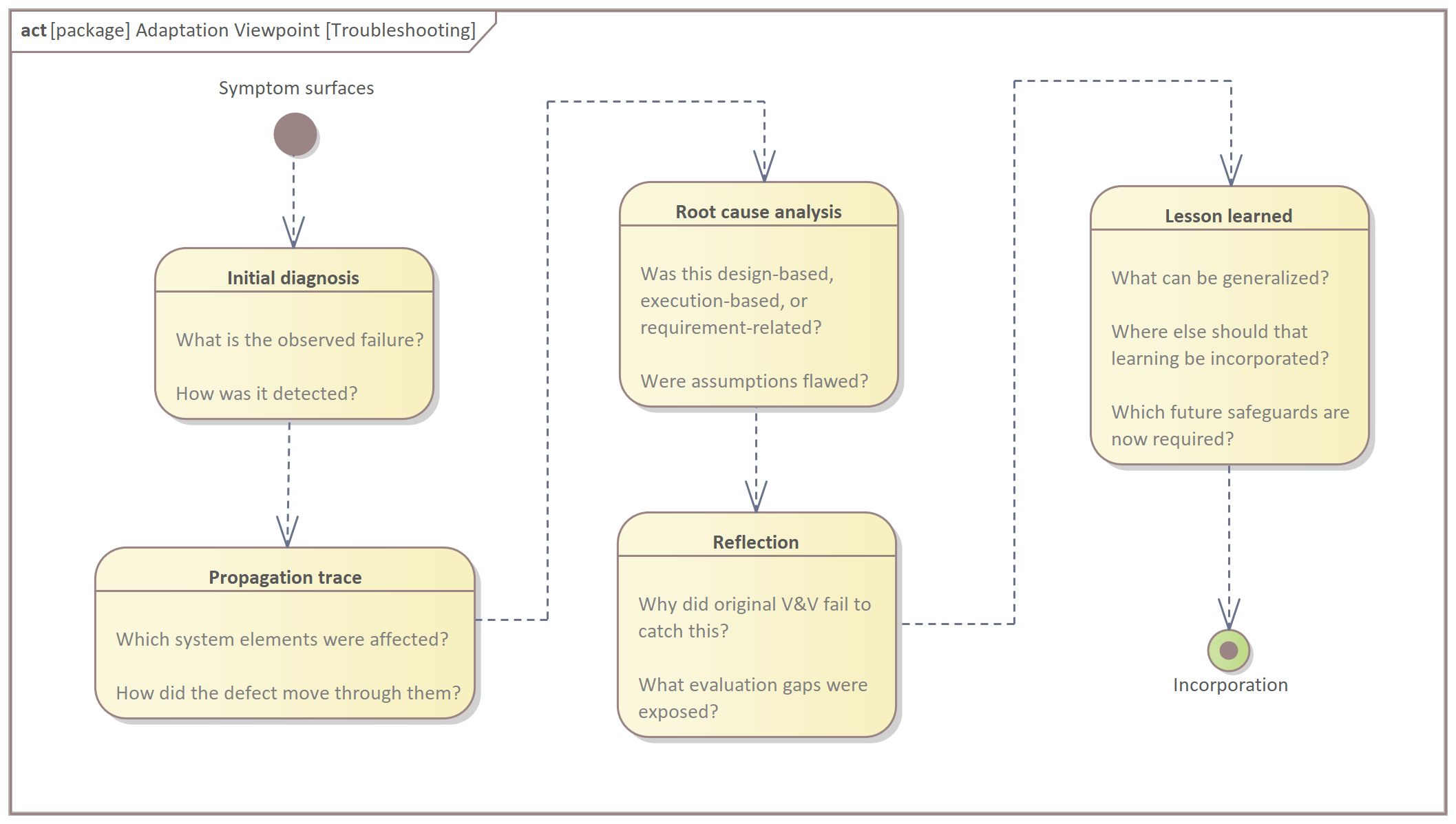
When defects are discovered, it’s not enough to patch them and move on. Effective troubleshooting seeks to locate the source, trace the pathway of propagation, and understand why detection failed earlier. This is where verification and learning converge.
Every defect is a signal of:
gaps in integration
mismatches in interfaces
unclear requirements
overlooked assumptions.
These signals only become insight when they’re interpreted. That means troubleshooting must examine:
Where the defect originated (source)
How it traveled through the system (propagation)
Why it escaped notice until now (detection failure)
What it implies about broader systemic vulnerabilities (scope)
The goal isn’t just to fix the current issue, but to refine the processes that allowed it to happen and remain hidden. Troubleshooting becomes a form of systems thinking by surfacing how behaviors, constraints, and decisions are conducted across domains
Importantly, we must avoid over-fitting fixes to singular symptoms. The temptation is strong to build protective scaffolding around the observed failure. But such scaffolding often decays when context shifts. Instead, verification should seek root causes, not just proximate ones, and ensure corrections harmonize across related concerns.
To prove that a particular defect caused a particular bug, one must determine through observation or analysis that:
the bug occurs when the defect is present
the bug does not occur when the defect is removed.
Re-verification then needs to be performed, to provide assurance that no other defects were introduced in the process of removing the original defect.
Done well, troubleshooting strengthens the endeavor itself. It improves coordination. It clarifies ambiguity. It exposes fragilities in assumptions and practices. And it sharpens judgment by turning unwelcome surprises into improved resilience.
The effects of instability
When the elements under scrutiny (be they components, subsystems, processes, or teams) are themselves unstable, assurance becomes a moving target. Instability can shift the meaning of “correctness” midstream, distorting both evaluation results and the validity of claims derived from them.
These instabilities may arise from:
Rapid iteration or ongoing design evolution Evaluated units change before verification completes, invalidating earlier conclusions or masking unfamiliar problems.
Poorly defined interfaces or incomplete specifications Ambiguities propagate unpredictably, making it unclear what is being tested or why results matter.
Behavioral inconsistency under varying conditions Units act differently depending on context, revealing fragility or hidden dependencies.
Shifting stakeholder expectations or requirements What was “fit for purpose” yesterday may no longer qualify today, rendering prior assurance moot.
Unstable units create an echo chamber of uncertainty: defects are harder to isolate, confidence is harder to build, and alignment with intent becomes tenuous. Assurance efforts lose traction because the terrain keeps shifting. And when instability isn’t acknowledged, misleading conclusions emerge. They can convey false security or premature readiness.
To troubleshoot effectively in this context, verification strategies must accommodate flux. That means incorporating traceability, version control, explicit assumption tracking, and synchronized validation cycles, so evidence stays tethered to the state of what’s being tested, and judgment remains relevant despite change.
The quest for coverage
Assurance efforts must confront an uncomfortable truth: complete coverage is impossible. The sheer number of potential states, inputs, interactions, and failure modes exceeds what can be evaluated exhaustively. This shifts the goal to sufficient coverage, calibrated to risk, complexity, and consequence.
Coverage isn’t about quantity; it’s about quality and relevance. A thousand test cases won’t help if they don’t interrogate the system’s real pressure points. And broad exploration means little without depth in areas where defects breed or propagate. That’s why coverage must be prioritized, weighted, and continually rebalanced as understanding evolves.
To do this well, agents need:
Explicit scoping criteria What matters most? Which capabilities, behaviors, or interfaces merit scrutiny, given the stakes?
Risk-informed heuristics Where are defects likely to emerge? Under what conditions would their impact be severe? Prioritization depends on knowing the terrain.
Traceability mechanisms Coverage must connect back to requirements, intent, and context, so gaps are visible, and evaluations remain meaningful.
Feedback integration As defects are found (or not), coverage strategies must adapt, shifting focus, deepening inquiry, and refining assumptions.
Without a coverage philosophy, verification becomes reactive and fragmented. With one, it becomes a disciplined search—not for everything, but for enough of the right things. Not proof of flawlessness, but confidence that what was tested matters, and what matters was tested well.
How effective are the evaluations?
Evaluation effectiveness is not binary. It lives in gradients, governed by purpose, context, method, and the kinds of errors being filtered. Even the best assessments may miss what they weren't designed to catch or fail to signal what they did observe with sufficient clarity.
To assess effectiveness, we must ask:
What are we trying to detect? Are we screening for:
Design misalignments?
Implementation defects?
Integration inconsistencies?
Deviations from intent or assumptions?
Different error types—skill-based slips, procedural inadequacies, knowledge-based mistakes—require different filters. Evaluations that are effective against one class may be inert against another.
Are the methods aligned? Evaluation activities must mirror the structure of the work they assess:
Procedural reviews work for low-ambiguity, static situations.
Simulation and scenario analysis expose nonlinear or emergent dynamic behavior.
Validation efforts test correspondence between as-built artifacts and intended outcomes.
An evaluation that isn’t structurally aligned with its target becomes decorative rather than diagnostic.
Are feedback loops functioning properly? Effective evaluations generate usable insights. But more importantly:
Are insights acted upon?
Do they lead to refinement in process, practice, or assumptions?
Does the system learn—individually or organizationally?
Evaluations without feedback loops become static audits, rather than adaptive assurance mechanisms.
What is evading detection, and why? An honest assessment of effectiveness requires surfacing:
What errors escaped filtering?
What errors were misclassified or misunderstood?
Why do those breakdowns occur - structurally, behaviorally, or cognitively?
This is the double-loop learning that reveals limitations not just in outputs, but in mechanisms themselves.
In short, evaluations are effective when they filter what matters, adapt as needed, and clarify limitations. They’re not merely about catching errors—they’re about knowing which errors matter and revealing the shape of our blind spots.
Back of napkin workload sizing example
Estimating workload isn’t merely arithmetic. It’s a form of bounded speculation, mapping assumptions, constraints, and uncertainties into something that can be coordinated across agents and timelines. When done well, it surfaces the latent drivers of risk, misalignment, and rework before they materialize.
Let’s say we’re estimating integration effort for a multi-unit system:
Known Interfaces Suppose there are fourteen known interfaces, each requiring test harnesses, emulators, or real subsystem integration.
Effort per Interface Average effort is estimated at 1.5 person-weeks per interface, including planning, setup, execution, and documentation.
Integration Complexity Factor Apply a complexity multiplier - say 1.2 - to account for asynchronous dependencies and tooling maturity.
Coordination Overhead Layer in 20% of effort for cross-team orchestration, churn, and sync-up activities.
Effort Estimation
Total Effort = 14 × 1.5 × 1.2 × (1.2) = 30.24 person-weeks Total Effort
But raw effort tells only part of the story. What matters is how this maps to:
Schedule feasibility Will this effort meet schedule need dates within available resources?
Risk exposure Which assumptions are fragile? What if interface definitions change mid-cycle?
Dependency timing Is interface availability aligned with testing activities?
Opportunity costs Could some units be initially stubbed instead of waiting for interfacing elements?
Workload estimation is as much about revealing pressure points as projecting timelines. The goal isn’t precision, it’s decision-enabling approximation, tuned to what matters.
Sizing demand
In a large system development of a million lines of code, approximately 50,000 defects will be injected by the team during coding (assuming use of experienced developers); assume half will be detected by tooling. Follow-on reviews, unit checks, standalone tests, integration tests, and system validation tests will each remove additional defects.
If one assumes that each of these verification steps has a yield of 50%, the residual defects remaining after these processes can be projected to be 25,000 * (0.5 / 5), leaving 2,500 defects remaining when the system entered service. Whether this is an acceptable number will entirely be dependent upon their severity and estimated time to repair. If higher quality is needed, possible supplementary actions include adding one or more additional verification steps, increasing the yield per verification stage (through better training or process changes), expanding the time provided to achieve broader verification coverage across stages, or reducing the amount of what must be verified).
Defect isolation
Defect removal time is the time it takes to find and repair a defect. For example, the time it takes to isolate and resolve a problem during validation testing is considerably greater than finding that same defect during a code review. This is principally because during a code review, you are finding the defect directly; when discovering it during validation testing, you must isolate the symptoms and determine the root cause in a much more complex (and typically more expensive) environment.
A defect removal model highlights how yield and defect injection rates interact over time during a component's development and usage, and what the resulting impact on resulting product quality will be.
In this context, an effective strategy for verification and validation will include:
Establishing an adequate set of activities to be able to accomplish the outcomes which are desired
Providing appropriate tools and guidance for performing these activities to maximize the yield realized from these actions
Performing an appropriate level of planning, so that the successive stages of these activities are sufficiently unique in their coverage to achieve the desired quality objectives
Monitoring the yields being realized by each of these defect removal stages, to ensure that this quality is actually being achieved
Collecting and analyzing information to accurately predict when artifacts will be sufficiently mature for a particular downstream purpose
These two parameters - defect removal time and yield - will impact what kinds of stages should be designed into verification and validation activities, so that errors are captured earlier (and thus more efficiently), and the desirable quality outcomes are achieved. The degree to which your own verification and validation strategies achieve these goals will have a significant impact on the timely delivery of your desired results!
Verification and validation aren't rituals, they’re lenses which reveal what's working, what’s fragile, and what’s misunderstood. They can transform failure into feedback, and complexity into clarity. But only if we wield them with discipline, purpose, and courage.
Ask yourself:
Are your assurance strategies tuned to your stakes?
Are your evaluations filtering what matters?
Are learnings incorporated into processes - or have processes degraded to just be the basis of audits?
Assurance is not just an engineering challenge; it’s a philosophical one. And every defect uncovered is a chance to do better, not just technically, but organizationally and conceptually.