

Throughput workflows and priorities
Treating symptoms may offer temporary relief, but unless you uncover and address the root issue, the problem will resurface—often more complex than before.

In the quiet chaos of production - where customer expectations outpace the capacity of delivery pipelines - workflow design becomes not just a matter of efficiency, but survival. Beneath the surface of neatly diagrammed project plans lurks a deeper challenge: how to manage the throughput of collective efforts when complexity, variability, and human limitations collide.
Throughput is the average rate of delivery of acceptable products through a production system. Architectures are often driven by throughput considerations, and the constraints which must be confronted drive the design of the system’s components. This throughput (and the reliability of assessments made of it) can be impacted by many factors, including the regularity of its inputs, the size and nature of queues which arise in processing throughout the system, the usable bandwidth and availability of channels for inputs, processing, and outputs, production losses due to coordination or quality issues, and impacts due to congestion.
Transforming bottlenecks
How can better prioritization, systemic insight, and a shift in mindset transform bottlenecks into breakthroughs and enhance throughput? Through workflows - repeatable pattern of activities that systematically organizes actors to transform information, materials, and energy into products. The Rational Unified Process illustrates this well as an example by breaking down work into sequential phases, each requiring time and effort to create intermediate work products necessary for shaping shippable features. It, and workflows like it, provide mechanisms which can enhance discipline in front-end activities - such as analysis, design, and construction - with expected payoffs in reducing rework in later phases. This makes sense as the isolation, management, and resolution of issues is easier while the issue can be isolated quickly within established contexts, rather than in later phases, when only symptoms are known and context is uncertain (see Figure 1).
But in practice, inputs often arrive according to business cycles, not customer demand. When the volume of incoming work outpaces the processing capacity of each work cell, bottlenecks form. Delays snowball, requiring more resources and rework downstream. These growing queues aren’t just nuisances; they signal a systemic imbalance between demand and throughput. What are these signals, and what can be done about it?
The Cost of Congestion
As queues expand, performance deteriorates. Teams divert resources reactively, which masks underlying inefficiencies rather than resolving them. Like rush-hour traffic, even a small dip in capacity can cascade into major slowdowns. The temptation to push incomplete work forward creates defects that emerge later, when they’re far more expensive to fix.
Why Prioritization Matters
Prioritizing before work enters the system may face resistance, but once customers experience shorter cycles and more predictable delivery, the value becomes clear. Smart prioritization isn’t about picking favorites - it’s about stabilizing flow so high-value work moves smoothly from start to finish.
Designing for Context
Unique products call for different development models. As Michael Cusumano notes, high-end custom systems require deep user engagement and expert tools, while mid-range offerings benefit from standardized processes that balance cost and customization. Mass-market products, by contrast, thrive on maximizing value for the average user.
Shining light on the invisible sources of variation
Manufacturing benefits from visual cues - inventory piles up where flow breaks down. Engineering lacks that visibility. Without tangible artifacts, inefficiencies go undetected, leading to unreliable throughput estimates. And traditional project plans often assume idealized, linear progress that’s rarely achieved.
Variation arises from two sources: assignable causes (clear execution failures) and random noise (systemic complexity). The former calls for better quality control; the latter demands systemic change.
Shaping Smarter Teams
Multi-skilled teams can adapt on the fly to balance queues and maintain cadence. Visual indicators - distinguishing customer-driven work from internal refactoring - support better decision-making. Over time, as teams learn their true pace and capabilities, they can make credible commitments to stakeholders.
But that only works if work enters the system in a ready state, with strict limits on in-progress inventory. Planning must begin with ideal assumptions - perfect timing, full capacity, zero defects - that are then adjusted for reality, making risks visible and prioritized accordingly.
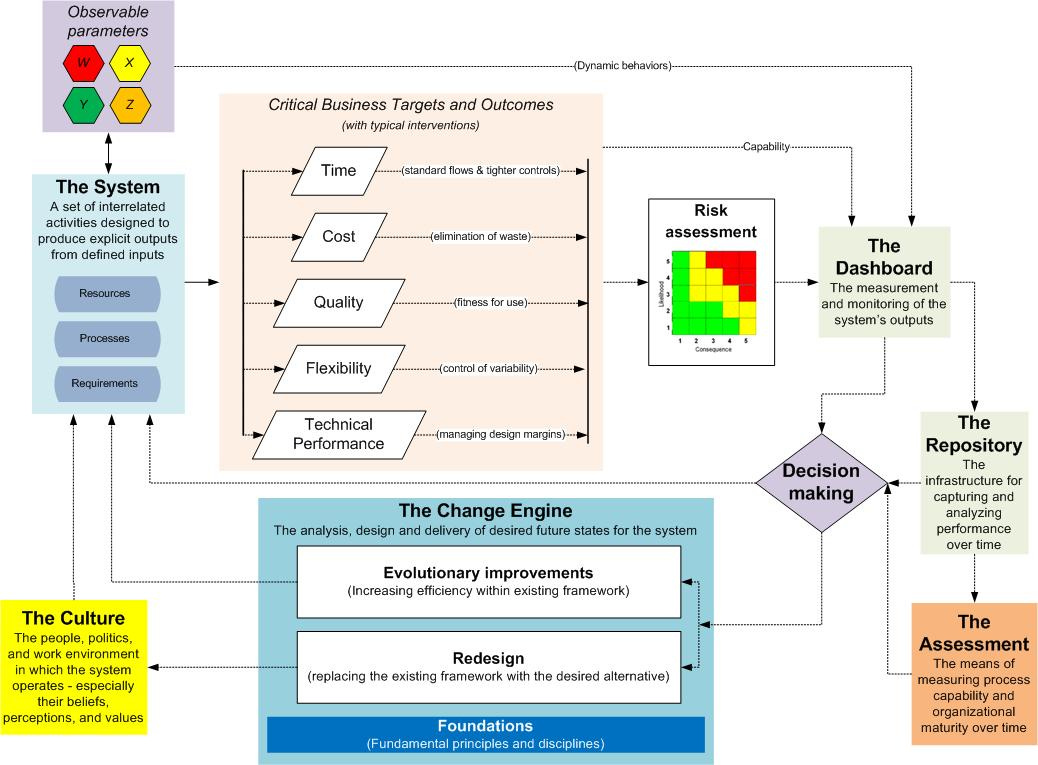
Optimizing throughput
A depiction of the elements involved in enhancing system throughput is shown in the Figure 2.
In Systems Thinking: Managing Chaos and Complexity, Jamshid Gharajedaghi describes the key requirements for improving the throughput of a system:
... even a simple throughput consists of a chain of events and activities need to be integrated. Since these activities are usually carried out by different groups in different departments of an organization, strong interfaces and effective coupling among them are a must... To design a throughput system, we need to:
Know the state of the art, as well as the availability and feasibility of alternative technologies and their relevance to the emerging competitive game.
Understand the flow, the interfaces between active elements, and how the coupling function works
Appreciate the dynamics of the system - the time cycle, buffers, delays, queues, bottlenecks, and feedback loops
Handle the interdependencies among critical variables, plus deal with open and closed loops, structural imperatives, and system constraints.
Have an operational knowledge of throughput accounting, target costing, and variable budgeting.
Given the constraints of technical risks and cultural adoption, and the inevitable uncertainties of implementation, I’d add four things to Gharajedaghi’s requirements:
Perform a reliable assessment of the dynamic interactions of existing system components to identify known bottlenecks
Determine what changes will provide the greatest performance returns for those roadblocks, considering investments in process capabilities, organizational maturity, and associated changes to subsystem components.
Define the target reference architecture that will be employed to incorporate these changes over time
Establish a roadmap for those changes
Allocate the target performance objectives to components within this roadmap to realize optimal sustainable performance improvements over time
Determine how much of this change can be successfully accomplished within the next iteration
Manage the change process for these components
In parallel, lean out the system, with particular focus on the system’s administrative functions, so that desired efficiencies are achieved over time.
While a theoretical peak throughput may be achievable for short bursts in a system, projections of change to sustainable throughput should be conservative, as such changes will only have impact as higher-rate throughput accumulates over time. Realizing such improvements will thus be a function of the sizing and resources available for servicing internal queues between and within components, and the ability of the system to adapt and reconfigure in response to changing demands.