


When we work with craftsmen to produce products, we rely on their talent, teamwork, and the match of their experience with the jobs to be done. As products grow in complexity, the agents responsible for these solutions must adapt to this complexity. If their performance does not scale as these increases in complexity emerge, demand for fixes will quickly outpace capacity. This makes it more difficult to locate or develop the required expertise and remain competitive.
For technical debt to be retired, and solutions to be produced more cost effectively, systematic, repeatable methods must be adopted that will produce more reliable outcomes for larger and more complex efforts.

Structured processes were initially introduced into such environments to mitigate the painful lessons associated with more ad-hoc methods. Yet an emphasis on process is frequently cited as a burden by developers that constrains them from pursuing their passion, and getting that which needs to get done, done.
Many have the perception that in-process quality doesn't matter, and that it is the ends, rather than the means, which matters. This is like saying that if water is clean, it doesn't matter where it has come from or what has been done with it. Today, countless development and manufacturing standards have been refurbished to attempt to address contaminants discovered after all processing is complete. Too often, organizations have adopted such standards as protectionist legislation intended to keep new competition out, rather than to guarantee higher quality outcomes.
Some quality definitions
To think through how to do this, some basic definitions are in order. A defect is anything that must be changed in a design or implementation because it detracts from the system's ability to meet stakeholder's needs completely and effectively. Defects can be identified, described, and counted; they are discoverable. The interrelationship between a defect, and the impacts from that defect (which may manifest through failure, as described below), is complex. Even simple defects can cause large problems, and not every defect can result in a failure (since it can be masked by the architecture, or latent until the required combination of events excites that flaw).
When agents make mistakes that result in defects, these lapses are typically described as injecting defects. The rate at which they do this is measurable and has been found to be between 50 and 120 defects per thousand lines of code. Half of these defects can be detected by modern tools during coding and unit checkout; an acceptable proportion of the remainder must be removed through down-stream evaluation activities. If those prove inadequate, they risk escaping into service and affecting operations for customers.
A bug is an observable anomaly which results from a defect and is discovered because an inconsistency with expected behavior is noticed by someone (who hopefully then records this observation so that it can be analyzed and traced to root causes).
Bugs typically manifest themselves through the following pattern:
A defect is introduced into a component, or into a related artifact (requirements, design, construction, or test) that is being produced during development. Note that the agents responsible for the component, the artifact, and this verification are often different individuals.
When a path through software logic (either within or across modular units) triggers this defect, one of two possibilities arises
the execution state of the code will no longer valid relative to the intentions of the design
the artifact will mislead those responsible for implementation or verification
In the case of defects, this invalid state can itself propagate throughout the system in other ways (as other execution sequences are traversed) to produce other invalid states
One or more of these invalid states may then eventually result in a bug - the externally visible condition - though this is dependent upon the combination of the execution sequences that are traversed.
A failure may further occur when one or more errors in the system occur, are propagated, and cause the system itself to enter an unsafe, incorrect, or unacceptable operational state.
The relationship between defects and failures is thus quite complex and is highly dependent upon the architecture of the system and the robustness of its implementation. Frequently, it isn't just one defect or error that leads to a failure, but a combination of several.
Leverage
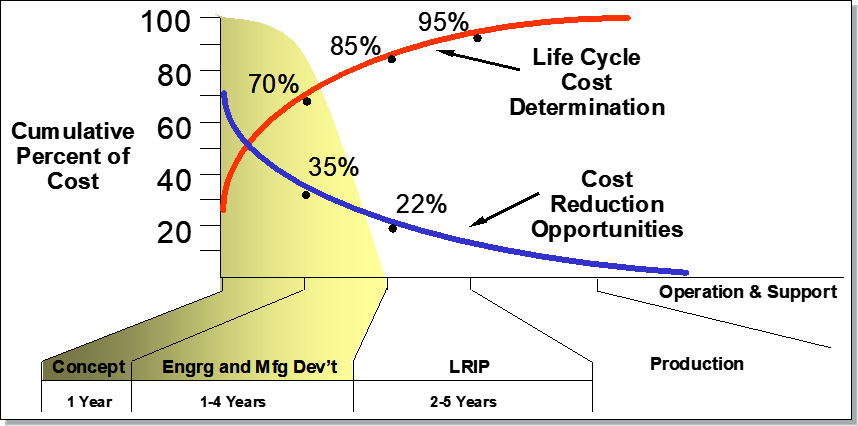
The US Defense Acquisition Guidebook has clear guidance about where endeavors have leverage in the cycle of system development and operations (see Figure 2): “The best time to reduce total ownership cost and program schedule is early in the acquisition process.”
What it takes
Development processes require diligence, effort, and appropriate tools to shortcut routine operations and help us avoid making slips; unfortunately, both people and tools are fallible. Would you drink water from a glass that was dirty, or drink from a catch basin that had a visible scum coating the inside of it? Probably not unless you had no other choice. Yet this insight can clarify the importance of having a well-designed process to produce a high-quality product. Believing that dirty pipes can produce pure water amounts to accepting the position that flawed tools or oblique human efforts will produce satisfactory results without accountability. Still, this myth lives on in the minds of both novices, some experts, and particularly bureaucrats.
Quality is difficult to measure directly. The operations necessary to transform inputs into acceptable outputs require multiple steps to be performed, across diverse environments, regardless of whether a business’s products are suitable for human consumption (like drinking water and software) or not.
If we stick with this plumbing analogy a bit, we can consider requirements to be like a supply of drinking water. The value stream that turns these requirements into useful progress is analogous to the links of pipe that fit together to carry water from its source to where it will be used. Each link is like the steps in the processes of a value stream. These processes may require defining what kind of product is needed, developing artifacts - designs, tests, and verification activities -which assure that the product complies with its requirements and does not introduce hazards to customers. If the links don’t interface properly, or there are missing links, value will be difficult to realize.
If the interconnections between these activities are like catch basins, buckets, and funnels, then someone must make sure the aggregated flow accumulating in these reservoirs is not stagnant or contaminated. Eventually something will exit from the pipeline, and with perseverance, it will be a quality product. The integrity of the pipeline will impact the quality of the output. There is no guarantee that even the most superb development processes will produce correct products and services.
Software quality has become a catch-all buzzword for a huge family of various methods geared either toward achieving better software or toward assessing how good software is. Each of these methods represents a different pipe link, and there are numerous ways of integrating these links that make sense; other combinations are nonsense. For example, putting the system level testing link in front of the processes for checking the requirements for ambiguity is foolish. Not all problems with water (or other products) are self-evident. Management of water quality is like other types of quality management activities and requires risks and opportunities to be managed across the entire water supply network.
Today’s quality practices can be categorized as either process-oriented or product-oriented methods. Process-oriented standards and methods focus on the effectiveness of implementing best practices; CMMI, DO-178, and ISO-9003 all expect a focus on quality across all critical activities, including assurance that this focus is sustained. In contrast, product-oriented verification approaches often presume that you can test quality into a system, rather than assuring that the people, methods, and information involved are all up to the task.
If we return to our analogy of a water system, flow-oriented methods function like connections that are distributed at separate locations along the pipe that allow software representations - whether in a design language or specification format - to be sampled to assess its correctness. The methods that perform assessments would be clustered towards the latter half of the pipeline, since in the earlier phases, code will not be available. These process-oriented methods would attempt to ensure that the original requirements were clean, and that every transformation through the development cycle was not contaminated. Clearly if the water quality is compromised at point A, then at a later point B, it will remain so, unless some filter is employed between A and B. Water doesn’t clean itself any more than incorrect software fixes itself, and water treatment has its limits.
People are prone to making mistakes
You might believe that to assess software quality, all you need are adequately predictive reliability estimation techniques. Most reliability models employ error history information from other situations and use them to forecast future error rates. The problem is that different models can make widely varying reliability projections for the same data, making it impossible to determine which model is the best predictor for a situation. Reliability will be a function of how many errors are injected and detected. Even direct measurement of software quality is less than practical.
Even ignoring all the potential sources of errors in generating test cases, defining test oracles, administrating test execution, and the fidelity differences between development, test, and execution environments, this is unlikely to change anytime soon; the people in the loop are usually the greatest source of defects.
Many of the remaining software assessment approaches focus on metrics. Over one hundred software metrics are in use today, typically focusing on measuring the structural or static properties of the system. The key problem with such metrics is that they do not capture the essence of software. Software is implemented by iterative refinement of mechanisms for transforming inputs into outputs, through a series of prescribed operations. This transformation is the essential characteristic of software development.
Each execution of a program involves a series of state transitions, where each machine state shapes the output. Exactly what effect a particular instruction has on the mapping between program inputs and program outputs is determined by the program’s input space distribution and the program’s control logic and instructions. Structural metrics cannot capture this dynamic aspect of software behavior. This lack of connection with the behavior of the software makes structural metrics especially poor as a predictor of in-service quality performance, though it remains essential for safety-critical applications.
Methods
Research has suggested using fault-injection methods to assess software quality by determining the rate of discovery of these defects. Such techniques purposely inject faults into your software and checks to see whether such injections are detected by other verification methods. However, the types of defects that affect most systems are broad, and the interactions that such defects produce simulates some of these events, and by doing so, it predicts how the software will behave in the future if these anomalous events were to occur.
This entire process of fault-injection relies upon statistics and pseudo-random fault-injection methods. Also, the actual process of instrumenting for the anomalies is quite complex. But the results can be most informative, particularly when you learn that your code doesn’t handle problems quite as well as you thought it would. This information provides an immediate quality improvement opportunity. Interestingly, software fault-injection methods, while they directly assess the behavior (i.e., goodness) of your code, also indirectly assess the goodness of your pipes.
By this, we mean that if software fault-injection methods determine that software is intolerant to either faults within itself or anomalies that can attack the software from external sources (such as human factor errors, failed external hardware, or failed external software), then we learn that the other software development processes failed to build in the necessary water filtering mechanisms. Code must be designed with the proper water filtering systems to ensure that the result from the pipe is clear of defects. If software is incapable of producing the outputs we want under even anomalous circumstances, then we cannot claim that the pipes are clean. And if over time it can be demonstrated (via the results of fault-injection) that the set of pipes you have used repeatedly do result in clean water, then you at least have anecdotal evidence that correlates your processes with the quality of your software.
The quality of your pipes is only one part of what determines the purity of potable water. It is myth to believe differently. Sadly enough, people at the highest levels in governments and corporations have all swallowed this lure, hook, line, and sinker. Quality software does not fail often and should never contribute to hazardous operation. Software development processes do not define software quality; the behavior of the system they are installed within does. Behavior is an intrinsic characteristic of software, and it can be viewed without regard to the software’s developmental history.
Before we can have faith in software standards and process models, it must be demonstrated that they have quantifiable effects on the quality of the software produced. Parnas once said: "It seems clear to me that not only is a ‘mature’ process not sufficient, but it may also not even be necessary."
The current popularity of process-oriented assessment techniques is, in part, a reaction to the intractability of performing adequate assessments of software projects. Unfortunately, the relationship between development processes and the attainment of some desired degree of product quality has never been adequately established. This problem is particularly acute for formal methods: forming the required processes does not give quantifiable confidence that the software, when released, will have the required reliability.
In short, testing measures the right thing - product reliability - but it often cannot measure it to the desired precision. Process measurements are more tractable, but they are more effective at managing the flow of work than they are at answering questions like 'how many problems remain'. Some basis must be established to build a data repository from which predictions of uncertain futures can converge with time. And with even more data from such projections, given some underlying framework for the underlying activities and characterization of effort, process yield, and product stability can be analyzed and form a basis for investments in means of production.